JavaScript (React + Express) Screen Recording App ?
Общие требования к реализации:
- запись должна состоять из видео и аудио
- у пользователя должна быть возможность просмотра и скачивания записи
- данные должны передаваться и сохраняться на сервере
- запись, сохраняемая на сервере, должна быть приличного качества, но весить мало
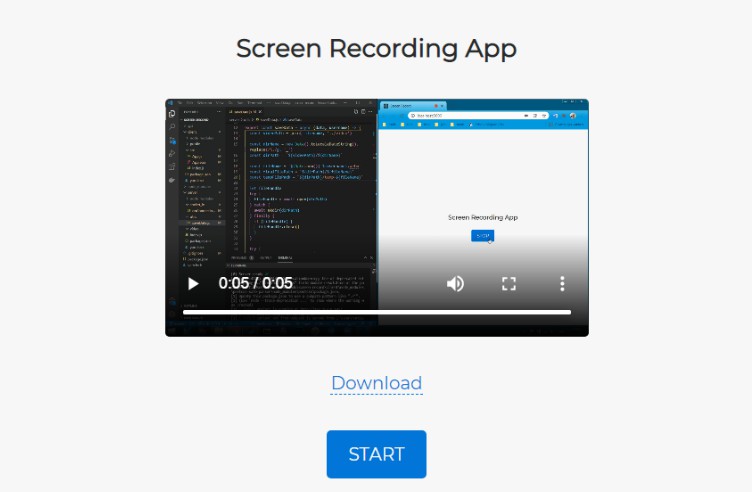
Скриншот:

К слову, здесь можно почитать о том, как разработать приложение для записи звука.
Основные технологии, которые мы будем использовать при разработке приложения:
Express.js–Node.js-фреймворкдля разработки веб-серверовReact.js–JavaScript-фремворкдля разработки пользовательских интерфейсовSocket.io– библиотека для разработки realtime-приложений с помощью веб-сокетовFFmpeg– инструмент для работы с видео и аудио
Здесь вы найдете шпаргалку по Express API, а здесь – руководство по работе с Socket.io.
Вместо React вы можете использовать любой другой фреймворк или ванильный JS. Если хотите, можете использовать TypeScript.
Подготовка и настройка проекта
mkdir screen-record && cd !$
yarn init -yp
yarn add concurrently
- создаем директорию для проекта и переходим в нее
- инициализируем
Node.js-проект - устанавливаем
concurrently
Определяем команды для запуска серверов в package.json:
"scripts": {
"server": "yarn --cwd server dev",
"client": "yarn --cwd client start",
"start": "concurrently \"yarn server\" \"yarn client\""
}
mkdir server && cd !$
yarn init -yp
yarn add express socket.io @ffmpeg-installer/ffmpeg fluent-ffmpeg
yarn add -D nodemon
- создаем директорию для сервера и переходим в нее
- инициализируем
Node.js-проект - устанавливаем основные зависимости и зависимость для разработки (про
ffmpegмы поговорим в разделе, посвященном разработке сервера)
Определяем тип кода сервера и команды для запуска сервера в package.json:
"type": "module",
"scripts": {
"start": "node index.js",
"dev": "nodemon index.js"
},
cd .. && yarn create react-app client
- возвращаемся в корневую директорию и создаем шаблон
react-приложенияв директорииclient
cd client
yarn add socket.io-client react-loader-spinner
yarn add -D sass
- переходим в директорию
client - устанавливаем основные зависимости и зависимость для разработки:
socket.io-client:socket.ioдля клиента – обязательноreact-loader-spinner: индикатор загрузки – опционально; большая коллекция лоадеров на чистомCSSsass: инструмент для стилизации – опционально; вы можете использовать любое решениеCSS-in-JSили обычныйCSS
Я также удалил из шаблона все лишнее (инструменты для тестирования, web-vitals и т.д.).
Единственное, что нужно добавить в package.json – это адрес сервера для проксирования запросов:
"proxy": "http://localhost:4000",
На этом подготовка и настройка проекта завершены.
Клиент
Весь код клиента содержится в файле scr/App.js.
import { useEffect, useRef, useState } from 'react'
import Loader from 'react-loader-spinner'
import io from 'socket.io-client'
import './App.scss'
Импортируем хуки, индикатор загрузки, клиента socket.io и стили.
const SERVER_URI = 'http://localhost:4000'
let mediaRecorder = null
let dataChunks = []
Создаем переменные:
- для адреса сервера
- экземпляра
MediaRecorder.MediaRecorder– это интерфейс, предоставляемыйMediaStream Recording API, для записи медиа - частей записанных данных
function App() {
// TODO
}
export default App
const username = useRef(`User_${Date.now().toString().slice(-4)}`)
const socketRef = useRef(io(SERVER_URI))
const videoRef = useRef()
const linkRef = useRef()
- генерируем случайное имя пользователя (например,
User_1234) – в реальном приложении имя пользователя, скорее всего, будет извлекаться из объектаuser, содержащегося в контексте, например,const { user } = useAuthContext(); const { username } = user - вызов
io(url, options)возвращает уникальный сокет клиента, используемый для передачи и получения данных от сервера. Нам достаточно указать адрес сервера. С полным списком настроек можно ознакомиться здесь - нам также нужны ссылки на
DOM-элементыvideoиaдля предоставления пользователю возможности просмотра записи и ее скачивания
Мы используем хук useRef для сохранения состояний между рендерингами.
const [screenStream, setScreenStream] = useState()
const [voiceStream, setVoiceStream] = useState()
const [recording, setRecording] = useState(false)
const [loading, setLoading] = useState(true)
screenStream– поток видео захваченного экранаvoiceStream– поток аудио из микрофонаrecording– индикатор состояния записиloading– индикатор состояния загрузки
Первое, что нам нужно сделать на клиенте – это уведомить сервер о подключении нового пользователя, сообщив ему имя пользователя:
useEffect(() => {
socketRef.current.emit('user:connected', username.current)
}, [])
Для отправки событий используется метод socket.emit(type, data), где type – строка, обозначающая тип события, а data – данные. Данными могут быть как примитивы, так и объекты. Для обработки событий используется метод socket.on(type, callback), где type – тип события, а callback – функция обработки, принимающая данные, отправленные с помощью socket.emit.
Далее нам необходимо захватить экран (получить поток видеоданных):
useEffect(() => {
;(async () => {
// проверяем поддержку
if (navigator.mediaDevices.getDisplayMedia) {
try {
// получаем поток
const _screenStream = await navigator.mediaDevices.getDisplayMedia({
video: true
})
// обновляем состояние
setScreenStream(_screenStream)
} catch (e) {
console.error('*** getDisplayMedia', e)
setLoading(false)
}
} else {
console.warn('*** getDisplayMedia not supported')
setLoading(false)
}
})()
}, [])
Для получения видеоданных из захвата экрана используется метод getDisplayMedia(), предоставляемый интерфейсом MediaDevices, входящим в состав Navigator.
К сожалению, на сегодняшний день данный метод поддерживается только десктопными браузерами, что составляет около 40% пользователей, но это все же лучше, чем ничего.
Следует отметить, что getDisplayMedia также умеет захватывать аудиоданные, но в настоящее время эту возможность поддерживают только Edge и Chrome, поэтому мы воспользуемся другим интерфейсом.
Примечание: Safari требует, чтобы пользователь явно выразил намерение на захват экрана. Для решения этой проблемы данный блок кода можно поместить в функцию startRecording (см. ниже).
Получаем аудиоданные из микрофона пользователя:
useEffect(() => {
;(async () => {
// проверяем поддержку
if (navigator.mediaDevices.getUserMedia) {
// сначала мы должны получить видеопоток
if (screenStream) {
try {
// получаем поток
const _voiceStream = await navigator.mediaDevices.getUserMedia({
audio: true
})
// обновляем состояние
setVoiceStream(_voiceStream)
} catch (e) {
console.error('*** getUserMedia', e)
// см. ниже
setVoiceStream('unavailable')
} finally {
setLoading(false)
}
}
} else {
console.warn('*** getUserMedia not supported')
setLoading(false)
}
})()
}, [screenStream])
Для получения аудио-потока используется метод getUserMedia. С поддержкой данного метода все намного лучше.
Не знаю точно, с чем это связано, но если мы попытаемся получить потоки одновременно, то получим только видеопоток, а попытка получения аудиопотока завершится ошибкой Permission denied. По крайней мере, такое поведение наблюдается в Chrome.
Мы готовы писать экран без звука, поэтому при возникновении любой ошибки, связанной с получением аудиопотока (включая отказ пользователя в предоставлении разрешения на использование микрофона), мы устанавливаем voiceStream в значение unavailable.
Также обратите внимание на расстановку setLoading(false). При инициализации приложения мы показываем пользователю индикатор загрузки до получения всех необходимых разрешений.
Глянем на разметку:
return (
<>
<h1>Screen Recording App</h1>
<video controls ref={videoRef}></video>
<a ref={linkRef}>Download</a>
<button onClick={onClick} disabled={!voiceStream}>
{!recording ? 'Start' : 'Stop'}
</button>
</>
)
Ничего особенного:
- элемент
videoдля просмотра записи - элемент
aдля скачивания записи - кнопка для запуска и остановки записи
Метод onClick выглядит так:
const onClick = () => {
if (!recording) {
startRecording()
} else {
if (mediaRecorder) {
mediaRecorder.stop()
}
}
}
Операция, выполняемая при нажатии кнопки, зависит от значения recording.
function startRecording() {
if (screenStream && voiceStream && !mediaRecorder) {
// TODO
}
}
Для выполнения кода функции startRecording требуется наличие потоков и отсутствие экземпляра MediaRecorder.
// обновляем состояние
setRecording(true)
// удаляем атрибуты
videoRef.current.removeAttribute('src')
linkRef.current.removeAttribute('href')
linkRef.current.removeAttribute('download')
Формируем медиа-поток:
let mediaStream
if (voiceStream === 'unavailable') {
mediaStream = screenStream
} else {
mediaStream = new MediaStream([
...screenStream.getVideoTracks(),
...voiceStream.getAudioTracks()
])
}
Состав медиа-потока зависит от доступности аудиопотока. Если аудиопоток недоступен, медиапоток будет состоять только из видеопотока. Иначе формируется объединенный поток из видеотреков видеопотока и аудиотреков аудиопотока. Для объединения потоков используется интерфейс MediaStream. С его поддержкой все хорошо.
Существует также другой способ объединения потоков:
const audioTracks = voiceStream.getAudioTracks()
audioTracks.forEach(track => {
screenStream.addTrack(track)
})
mediaStream = screenStream
mediaRecorder = new MediaRecorder(mediaStream)
mediaRecorder.ondataavailable = ({ data }) => {
dataChunks.push(data)
socketRef.current.emit('screenData:start', {
username: username.current,
data
})
}
mediaRecorder.onstop = stopRecording
mediaRecorder.start(250)
Создаем экземпляр MediaRecorder.
Метод start принимает количество мс. По истечении указанного времени вызывается событие dataavailable. Данные содержатся в свойстве data.
Мы помещаем части записанных данных в массив dataChunks и отправляем их на сервер с помощью сокета. В данном случае мы делаем это 4 раза в секунду.
По окончанию записи вызывается функция stopRecording:
function stopRecording() {
// обновляем состояние
setRecording(false)
// сообщаем серверу о завершении записи
socketRef.current.emit('screenData:end', username.current)
// об этом хорошо написано здесь: https://learn.javascript.ru/blob
// дополнительно:
// https://developer.mozilla.org/en-US/docs/Web/API/Blob
// https://developer.mozilla.org/en-US/docs/Web/API/URL/createObjectURL
const videoBlob = new Blob(dataChunks, {
type: 'video/webm'
})
const videoSrc = URL.createObjectURL(videoBlob)
// источник видео
videoRef.current.src = videoSrc
// ссылка для скачивания файла
linkRef.current.href = videoSrc
// название скачиваемого файла
linkRef.current.download = `${Date.now()}-${username.current}.webm`
// выполняем сброс
mediaRecorder = null
dataChunks = []
}
На этом с клиентом мы закончили.
Сервер
Структура проекта (директория server):
- socket_io
- onConnection.js - функция для обработки подключения
- utils
- saveData.js - функция для сохранения записи
- video - директория для записей
- index.js - код сервера
- ...
Начнем с файла, содержащего код сервера (index.js):
import express from 'express'
import http from 'http'
import { Server } from 'socket.io'
import { onConnection } from './socket_io/onConnection.js'
Импортируем библиотеки и функцию для обработки подключения.
const app = express()
const server = http.createServer(app)
const io = new Server(server, {
cors: {
origin: 'http://localhost:3000'
}
})
Создаем экземпляры express-приложения, сервера и socket.io. Обратите внимание на настройку cors. Данная настройка является обязательной.
io.on('connection', onConnection)
server.listen(4000, () => {
console.log('Server ready ? ')
})
Регистрируем обработку подключения и запускаем сервер на порту 4000.
Функция обработки подключения (socket_io/onConnection.js)
import { saveData } from '../utils/saveData.js'
const socketByUser = {}
const dataChunks = {}
- импортируем функцию для сохранения записи
- создаем переменные:
- поисковую таблицу
идентификатор сокета - имя пользователя - для частей записанных данных. Обратите внимание на то, что в отличие от клиента, где мы использовали массив, здесь мы используем объект
export const onConnection = (socket) => {
// TODO
}
Функция для обработки подключения принимает сокет.
socket.on('user:connected', (username) => {
if (!socketByUser[socket.id]) {
socketByUser[socket.id] = username
}
})
Обрабатываем подключение нового пользователя посредством записи имени пользователя в поисковую таблицу.
socket.on('screenData:start', ({ data, username }) => {
if (dataChunks[username]) {
dataChunks[username].push(data)
} else {
dataChunks[username] = [data]
}
})
Обрабатываем получение от клиента частей записанных данных. dataChunks – это также поисковая таблица имя пользователя - массив данных.
socket.on('screenData:end', (username) => {
if (dataChunks[username] && dataChunks[username].length) {
// вызываем функцию для записи данных,
// передавая ей массив данных и имя пользователя
saveData(dataChunks[username], username)
dataChunks[username] = []
}
})
Обрабатываем завершение записи.
socket.on('disconnect', () => {
const username = socketByUser[socket.id]
if (dataChunks[username] && dataChunks[username].length) {
saveData(dataChunks[username], username)
dataChunks[username] = []
}
})
Аналогичным образом обрабатываем отключение клиента на случай закрытия вкладки браузера во время записи – в этом случае событие screenData:end отправлено не будет. В худшем случае мы потеряем 250 мс видео (mediaRecorder.start(250)).
Функции для сохранения записи (utils/saveData.js)
import { Blob, Buffer } from 'buffer'
import { mkdir, open, unlink, writeFile } from 'fs/promises'
import { join, dirname } from 'path'
import { fileURLToPath } from 'url'
Импортируем утилиты из Node.js. Обратите внимание: Buffer появился в Node.js недавно и является экспериментальным. Возможно, вам потребуется обновить Node.js (как это пришлось сделать мне на домашней машине), воспользоваться чем-то вроде node-blob или найти другое решение для создания временного видеофайла.
import { path } from '@ffmpeg-installer/ffmpeg'
import ffmpeg from 'fluent-ffmpeg'
ffmpeg.setFfmpegPath(path)
fluent-ffmpeg– обертка дляffmpeg'@ffmpeg-installer/ffmpeg– для работыfluent-ffmpegтребуется наличие локально установленногоffmpeg. Данная утилита именно это и делает, предоставляя путь кffmpeg, который передаетсяfluent-ffmpeg
// путь к текущей директории
const __dirname = dirname(fileURLToPath(import.meta.url))
// функция принимает данные для сохранения и имя пользователя
export const saveData = async (data, username) => {
// TODO
}
// путь к директории для записей
const videoPath = join(__dirname, '../video')
// название директории для сегодняшних записей - например, 21_11_2021
const dirName = new Date().toLocaleDateString().replace(/\./g, '_')
// путь к этой директории
const dirPath = `${videoPath}/${dirName}`
// название файла, включающее имя пользователя
const fileName = `${Date.now()}-${username}.webm`
// путь к временному файлу
const tempFilePath = `${dirPath}/temp-${fileName}`
// путь к итоговому файлу
const finalFilePath = `${dirPath}/${fileName}`
let fileHandle
try {
fileHandle = await open(dirPath)
} catch {
await mkdir(dirPath)
} finally {
if (fileHandle) {
fileHandle.close()
}
}
Создаем директорию для сегодняшних записей (один раз).
try {
// TODO
} catch {
console.log('*** saveData', e)
}
const videoBlob = new Blob(data, {
type: 'video/webm'
})
const videoBuffer = Buffer.from(await videoBlob.arrayBuffer())
await writeFile(tempFilePath, videoBuffer)
Создаем временный видеофайл. Как видите, наш файл имеет формат WebM, потому что он классный (я имею ввиду формат).
ffmpeg(tempFilePath)
.outputOptions([
'-c:v libvpx-vp9',
'-c:a copy',
'-crf 35',
'-b:v 0',
'-vf scale=1280:720'
])
.on('end', async () => {
await unlink(tempFilePath)
console.log(`*** File ${fileName} created`)
})
.save(finalFilePath, dirPath)
Конвертируем временный файл с помощью ffmpeg:
- передаем
ffmpegпуть к временному файлу - устанавливаем настройки конвертации (см. ниже)
- передаем методу
saveпуть для сохранения конвертированного файла и путь к директории для временных файлов (для этого можно завести отдельную директорию) - удаляем временный файл после конвертации
К слову, аналогичная конвертация + объединение видео- и аудиофайлов в один видеофайл формата WebM с помощью CLI выглядит так:
ffmpeg -i video.webm -i audio.webm -c:v libvpx-vp9 -c:a copy -crf 35 -b:v 0 -vf scale=1280:720 -shortest merged.webm
Настройки:
-c– это кодек-c:v– кодек для видео-c:a– кодек для аудио
В качестве кодека для видео мы указываем libvpx-vp9 (VP9). Это связано с тем, что (если я все правильно понял) для создания файла формата WebM требуется, чтобы видео содержалось в контейнере VP8 или VP9, а аудио – в Opus или Vorbis. Аудио-дорожку мы просто копируем указывая copy в качестве кодека. Не уверен, что нам здесь это нужно. Это артефакт моих экспериментов по разделению и слиянию видео- и аудиопотоков.
Примечание: в Safari при установке кодеков возникает ошибка.
-vf scale=1280:720– это разрешение. Как правило, чем меньше, тем меньше размер файла и хуже качество видео (это зависит от разрешения исходного видео)-crf 35 -b:v 0– эти настройки я взял отсюда(см. разделConstant Quality) Вот еще один источник истины. В названных источниках рекомендуется конвертировать видео в два прохода (pass), но я стремился к максимальной скорости конвертации и меня устраивало небольшое снижение качества
crf – это постоянный коэффициент скорости(Constant Rate Factor), а b:v – битрейт видео.
С полным списком настроек можно ознакомиться здесь.
Скорость конвертации сильно зависит от вычислительных мощностей, которыми мы располагаем. В среднем время конвертации равняется продолжительности видео. Конвертированный файл получается примерно в 3 раза меньше оригинала. При этом качество видео страдает не сильно. Я небольшой специалист по работе с видео, с ffmpeg начал работать недавно, поэтому буду рад любым замечаниям на этот счет.
На этом с сервером мы закончили.
Тестирование
Находясь в корневой директории проекта, выполняем команду yarn start.
По адресу http://localhost:4000 запускается сервер для разработки, а по адресу http://localhost:3000 – сервер для клиента. В браузере открывается новая вкладка.
Сначала браузер запрашивает разрешение на захват экрана.

Затем разрешение на захват микрофона.
Предоставляем ему эти разрешения. Что интересно, разрешение на захват микрофона запрашивается один раз, а на захват экрана – при каждом запуске приложения.

Нажимаем на кнопку Start. Начинается запись.
Нажимаем на Stop. Запись прекращается. У видео появляется источник, ссылка для скачивания становится активной.
Скачиваем файл. Запускаем запись. Любуемся своим экраном и наслаждаемся своим голосом ?
Заглядываем в server/video, находим там директорию, например, 21_11_2021, а в ней файл, например, 1637480942425-User_0711. Сравните скачанный файл с конвертированным на предмет размера и качества.
Поздравляю, теперь вы умеете записывать экран пользователя и сохранять запись на сервере.
The end.