spresso-search
Visual metasearch engine built with React, Redux, Express, and TypeScript.
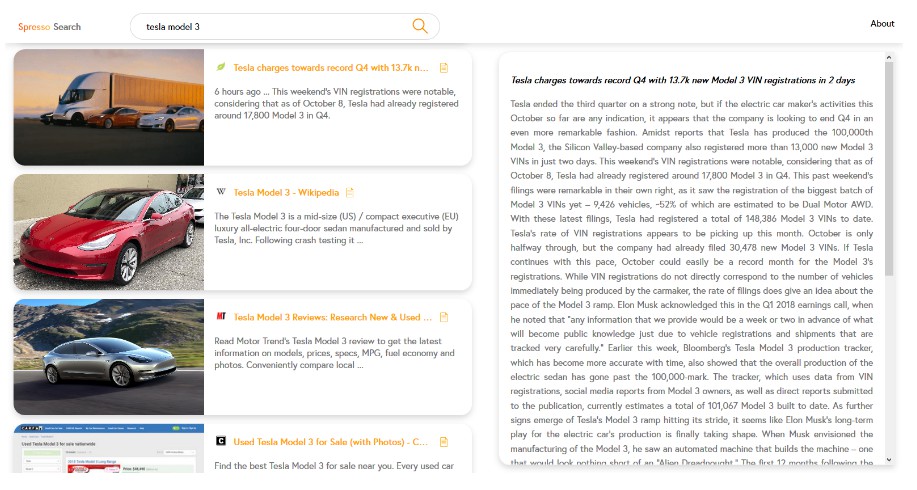
Spresso search scrapes search results from Google using the node x-ray library, and uses the same library to scrape obtain meta-information on webpages (preview images, favicons). There is a screenshot feature, which takes screenshots of sites that don't have meta preview images in their HTML.
There is also a text-outline feature, powered by node-unfluff, which scrapes text content from web pages(ideal for articles & other text-rich pages), allowing the user to read the contents of a web page in clean, formatted text and without leaving the Spresso Search site.