? Mirror
A Natural Language Interface for Data Querying, Summarization, and Visualization
Mirror is a project that aims to build and share a natural language interface for data querying, summarization, and visualization. This repository contains the code for the user interface (UI) as well as the code for creating SQL queries, summaries, and visualizations.
Overview
Data exploration and analysis are critical tasks for organizations, but can be challenging due to technical expertise requirements and complex tools.
Mirror is an open-source platform for data exploration and analysis powered by large language and code models, GPT-3 and Codex. It offers an intuitive natural language interface for querying databases, automatically generates SQL commands, and provides visualizations for data understanding.
Mirror is designed to be flexible and suitable for both experienced data analysts and non-technical professionals. It is a “plug-and-play” tool that leverages pretrained models, eliminating the need for annotated data. The platform is demonstrated through two use cases: automatic question answering for sports with real-time updates, and OSS Insight Data Explorer for open-source event analysis.
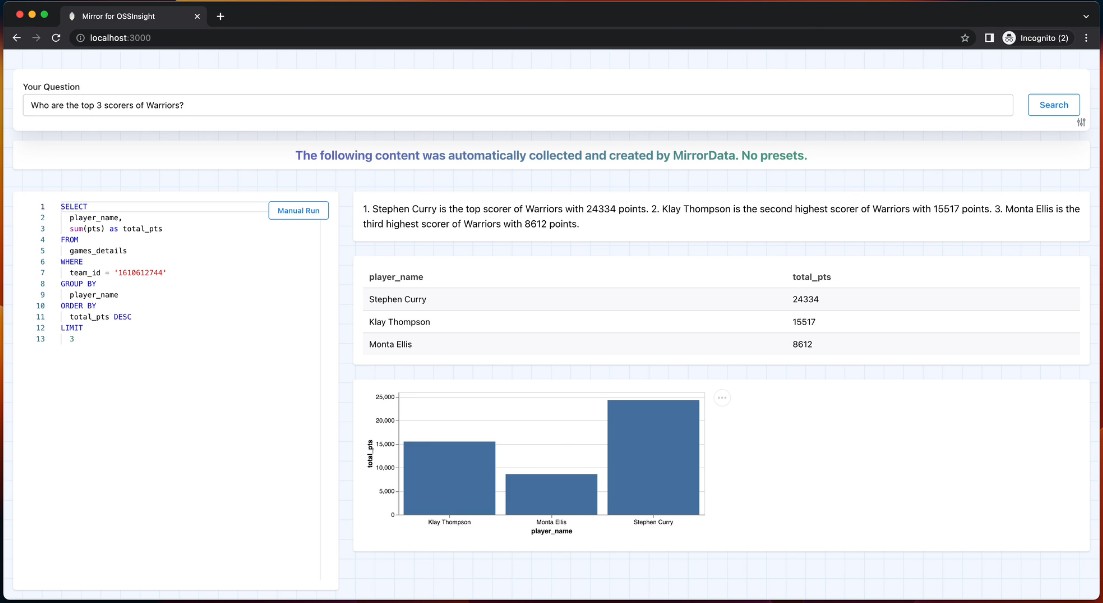
The components and workflow of Mirror in the data query stage. The red dashed lines indicate human-in-the-loop components that can allow user interaction or editing. Query auto-completion with metadata is omitted

Future work includes exploring dialogue-based multi-round query to improve self-correction ability and user interaction through a dialogue-like interface, by combining ChatGPT and the SQL engine.
Development
Dependencies
Mirror uses the following technologies:
-
React
-
Matine.dev
-
Vega
To set up a development environment, you will need the following:
- Node.js version 16 or higher
- Yarn as the package manager
Running the Code
Follow these steps to run the code locally:
-
Set environment variables
# .env.local # Your OpenAI API key OPENAI_API_KEY={{REPLACE_IT_WITH_YOUR_OPENAI_API_KEY}} # Your Postgres URL, e.g. postgres://user:password@localhost:5432/dbname PG_URL="{{REPLACE_IT_WITH_YOUR_POSTGRES_URL}}" # Enable basic auth # BASIC_AUTH={username}:{password} -
Install the dependencies with
yarn install -
Run
yarn devto start the development server
Deployment
To deploy Mirror, follow these steps:
-
Build the web static server
yarn build & yarn export -
Build a Docker image
# Build Docker image docker build -t mirror-data/mirror . # Multi-arch build docker buildx build --platform linux/amd64,linux/arm64 -t mirror-data/mirror .
Citation
Please cite the repo if you use the code in this repo.
@misc{mirror,
author = {Canwen Xu and Julian McAuley and Penghan Wang},
title = {Mirror: A Natural Language Interface for Data Querying, Summarization, and Visualization},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/mirror-data/mirror}},
}
Authors
Acknowledgments
Mirror was a participating and award-winning project at PingCAP TiDB Hackathon 2022. We would like to thank PingCAP, Inc. for the generous awards and support. The intellectual property of OSS Insight (including but not limited to its Mirror integration) is owned by PingCAP, Inc.