Modern React + DataScript + Hooks
Most of the time when you are writing SPA using State Management lib such as Redux – you have to manually write and read the data. Its up to the user to
figure out how th store the data. This can be hard to scale, since we dont know what or how will our app grow or what will be our clients needs in the future.
Also when retrieving data from store, developer has to keep in mind of how the data was stored
For example lets look at following store of of a twitter application
const twitterReduxStore = {
users: {
byId: {
user1: {
id: "user1",
name: "john doe",
handle: "@john.doe",
tweets: [1],
followers: ["user2"],
},
user2: {
id: "user2",
name: "jane doe",
handle: "@princessjane",
tweets: [2],
followers: ["user1"],
},
},
allIds: ["user1", "user2"],
},
tweets: {
byId: {
1: {
id: 1,
title: "DataScript rocks",
likes: ["user1", "user2"],
},
2: {
id: 2,
title: "YNWA!",
},
3: {
id: 3,
title: "JavaScript can be interesting",
likes: ["user1", "user2"],
},
},
allIds: [3, 2, 1],
},
};
In the following store, we have users and tweets
- users is modelled as a map datastructure, and user Id is the key following by the user map as the value.
- user has the following attributes:
- id,
- name,
- twitter handle
- tweets array containing ids of all the tweets they have authored
- followers array containing ids of user who follow this user
- tweets are are map with id key and tweet as value
- tweet has the following properties:
- id
- title
- likes, an array containing ids of users who liked this tweet
Now this is the best practice for structuring Redux State Tree. They recommending normalizing state shape.
Basics concepts, according to the documentation are:
The basic concepts of normalizing data are:
- Each type of data gets its own “table” in the state.
- Each “data table” should store the individual items in an object, with the IDs of the items as keys and the items themselves as the values.
- Any references to individual items should be done by storing the item’s ID.
- Arrays of IDs should be used to indicate ordering.
What are the benefits of Data Normalization?
- Because each item is only defined in one place, we don’t have to try to make changes in multiple places if that item is updated.
- The reducer logic doesn’t have to deal with deep levels of nesting, so it will probably be much simpler.
- The logic for retrieving or updating a given item is now fairly simple and consistent. Given an item’s type and its ID, we can directly look it up in a couple simple steps, without having to dig through other objects to find it. (thats a lie)
Now whare the cons?
- You have to manually write all the things down – maintenance cost?, What if we dont need a certain entity, then the developer has to go there and manually remove the data
- Leads to more code, more code is a liability.
- Manually normalize datas – usually API’s send nested data. Authors recommend using tools such as Normalizr
- You have to be very disciplined if you want to write “clean” code
- Querying data is done manually – developers now have to know how to retrieve the data that they need (more overhead)
Normalizing Redux tries to mimic traditional relational database, its not data normalization is only one issue it solves.
What about write and retrieving data?
Question 1:
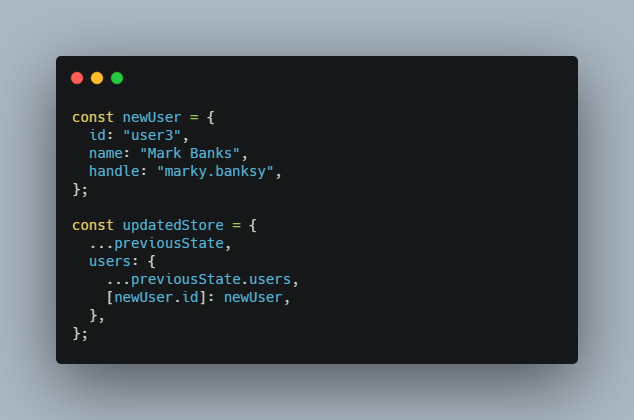
Now lets see side by side how we would add new user in our database
const newUser = {
id: "user3",
name: "Mark Banks",
handle: "marky.banksy",
};
const updatedStore = {
...previousState,
users: {
...previousState.users,
[newUser.id]: newUser,
},
};
Question 2:
Lets say @john.doe just won $1000 lottery and and wants to let everyone know about it. How do we update the state tree. Its a three step process
-
First create tweet
-
Second find the john.doe by twitter handle (this how we have designed the state tree).
-
Third Once found, update his tweets array i.e add the new tweet id and finally update the state tree as well as update the tweets state tree with with id of the new tweet as the key and the tweet map as the value
// step 1: new tweet
const newTweet = {
id: 3,
tweet: "just won $1000, huzzah",
};
// O(n) operation, we could have easily found john by his id
// which has a time complexity of O(1)
// lets say we only have access to his twitter handle when he tweets
const john = Object.values(twitterReduxStore.users).find(
(user) => user.handle === "@john.doe"
);
// step 3
const updatedJohn = {
...john,
tweets: john.tweets.concat(newTweet.id)
}
const newStateTree = {
...twitterReduxStore
users: {
...twitterReduxStore.users,
[updatedJohn.id]: updatedJohn,
},
tweets: {
...twitterReduxStore.tweets,
[newTweet.id]: newTweet
},
}
Question 3
What is the user wants to delete a tweet?
- Then we’d have to the similar process as above i.e remove tweet from the tweets tree and remove the id of the tweet from the users’ tweets array
- We’d also have to remove the id from tweetIds array
Question 4
How do we keep track of who liked the tweets?
- We’d have to update the tweets object by adding
likeskey and giving ids of the users as values
Question 5
What if we want to find users by email or twitter handle since they are unique – we can but it will be expensive 0(n), our state tree is optimized for for user id.
Other Questions
- What about aggregations, derived data etc
What can we learn from this
- User/Application Developer is responsible for designing, evolving the state tree
- Lots of manual procedural code (map, filter)
- Its works great in the beginning but as the application grows, its hard to
evolve the state tree. - Lets say the Developer quits job, and a new developer is over takes his/her role. That developer has to learn every thing about the state tree. Where each data is stored and how it is stored and how it is retrieved. Each developer has his/her own opinions as to how to store and evolve data. This can lead to what I call state tree in consistency and I have seen this a lot in production applications. Since its up to developer to manage and grow the state tree, one developer can decided to store the data in array and other developer can decide to store in a map with id as indexed.
In reality this is the current state of frontend state management frameworks.
And this is the source of MOST of the bugs. Developers are humans, and when you manually manage state, there is a high probablity that code is buggy.
So how do we solve this?
Lets look at backend developers and how they manage data. Backend developers use databases such as relational or non relational to automatically manage data. If they are using relational DB, then they can harness the power of SQL, to retrieve data. SQL is very powerful or Datalog Databases like Datomic, both of the which is very powerful. It is declarative and the code is very to understand.
Now what do you think would happen, if backend developer decides to use tools like frontend developer to manage data.
- The business will go bankrupt within 6 months XD
- Backend Developer will think that you are joking for even mentioning that, or if you are serious then they will unfollow you on twitter for having horrendus opinions.
Most of the state management problems that frontend developers face has already been solved in the backend i.e Databases
May be that is that we need. A database that is very cheap to create, holds data only on run time, has all the query power and has transaction cabalities.
If only such a technology existed, a lot of manually written code would simply disappear. Luckily, a dude named Nikita (@tonsky) has infact written such library called DataScript.
In the next section, we will learn everything about DataScript and learn howe we can use this amazing piece of technology to solve our state problems
in React Applications
What is DataScript
- DataScript is an In Memory Database based on Datomic (Datomic is an append only Database) and Datalog Query Engine for Clojure/Script and JavaScript.
In Memory Database
- Database of Facts called Datoms.
- Contains set of Datoms
- Very cheap to create: simple as creating a object
Datom
- Datom is a tuple consisting of the 4 components
[entity attribute value transaction], where
entity – The first component of a datom, specifying who or what the datom is about. Example person, school
attribute – Something that can be said about an entity. For example: person has attributes such as name, age, gender etc.
value – Third component of the datom. Value of the attribute. For example john is an entity whose age is 22. 22 is the value.
transaction – is a timestamp represending when was the datom/fact added to the database.
Example: This is what a datascript database looks like
[[john :person/name "John" 1234]
[john :person/age 22 1234]]
Here:
- John is an entity
- John has two attributes: name and age and value of “John” and 22 respectively
- Both the facts about John was added at the same time
Datascript database is a huge collection of datoms
In a relational database, each of those (title, release year, and genre) would be considered “fields” in a “table”. In Datomic, each of those is an , which can be associated with an.
Operations suppoed by Datascript Database
Some of the operations suppored by this database are
- Add facts
- Remove facts
- Query Data (via Query Engine)
One thing to note is that DataScript DB contains only currently relevant datoms. There’s no history tracking at DB level. When datom is removed from a DB, there’s no trace of it anywhere. Retracted means gone.
Datalog Query Engine
What is a datalog?
- Datalog is a declarative database query language with roots in logic programming. Datalog has similar expressive power as SQL.