
Static Code Analysis Toolkit for Vulnerability Detection and Mitigation.
Demonstration
ScanRE.Static.Code.Analysis.Toolkit.mp4
Or view the video on YouTube: ScanRE — Static Code Analysis Toolkit
- View our presentation: MumbaiHacks – ScanRE
Motivation
- To help improve the security posture of open-sourced software in the industry ?
Alert Fatigue!
Frequent alerts about cybersecurity threats can lead to so-called “alert fatigue” which numbs the staff to cyber alerts, resulting in longer response times or missed alerts. The fatigue, in turn, can create burnout in IT departments, which then results in more turnover among the staff. When replacement personnel are hired, the cycle begins again.
That’s according to a recently released report conducted by International Data Corporation (IDC) for Critical Start, a cybersecurity consulting and managed detection and response company. IDC surveyed more than 300 U.S.-based IT executives at companies with 500 or more employees. It found that:
- Security staff spend an average of 30 minutes for each actionable alert, while 32 minutes are lost chasing each false lead.
- Companies with 500-1,499 employees ignore or don’t investigate 27% of all alerts.
- The figure is nearly a third (30%) for companies with 1,500-4,999 employees and 23% for those with 5,000 or more employees.

- Most of modern infrastructure relies on open-source software.
- Developers blindly import and use vulnerable or malicious code.
- Most people aren’t aware of best practices.
- Finding vulnerabilities is a mostly manual and tedious process.
Features

- Vulnerability Analysis, Detection and Mitigation
- Quick Scan — Scans the whole codebase
- DeepScan — not only scans the codebase, but its direct dependencies
- Provides visual insights and severity tracking
- Hooked up GPT-4 for Vulnerability Mitigation Suggestions
What is Static Code Analysis?
Static analysis is a method of debugging that is done by automatically examining the source code without having to execute the program. This provides developers with an understanding of their code base and helps ensure that it is compliant, safe, and secure. To find defects and violations of policies, checkers perform an analysis on the code.

They operate by querying or traversing the model, looking for particular properties or patterns that indicate defects. Sophisticated symbolic execution techniques explore paths through a control-flow graph. The data structure representing paths that might be traversed by a program during its execution. A warning is generated, if the path exploration notices an anomaly.
Architecture
In a hackathon, the main tradeoff is between the code quality, the features and finally, the time we have been given to come up with a complete solution. We, therefore, had to take a decision regarding which features we were to prioritize over others and which features we could leave until the end. It always helps to architect your solution before you put down any code, and that is what we did.
- The project contains 2 broad directories.
*
├───mh-backend
└───mh-frontend
Frontend
- We have used Vite + React. Why?
Backend
- The backend was written in Python, i.e. using the Flask framework.
Detailed instructions can be found in the individual directories on setting up the project.
- For those who want to tinker around with the output of our backend system, we’ve included a sample output.json file in the root directory.
Have fun ?
A high level layout of our system is shown below.

Individual components
* The OSS Review Toolkit (ORT) is a FOSS policy automation and orchestration toolkit which you can use to manage your (open source) software dependencies in a strategic, safe and efficient manner.
* Semgrep is a fast, open-source, static analysis engine for finding bugs, detecting vulnerabilities in third-party dependencies, and enforcing code standards. Semgrep analyzes code locally on your computer or in your build environment: code is never uploaded.
We’ve made extensive use of docker and celery to ensure that we are able to tackle the asynchronous nature of our task, i.e. scanning multiple files of code, each having different sizes across multiple repositories. A high level architecture of celery is shown below.

We decided to go ahead and integrate these two, i.e. semgrep and ORT together with ChatGPT (GPT-4) so that we could ensure that we get the best of all worlds (Scanning user code as well as that of dependencies as well as get suggested mitigations)
And that was the heart of our solution. It reduces alert fatigue, allows the security team to focus on what matters and helps the team better utilize existing resources.
A win-win all around ?
Screens
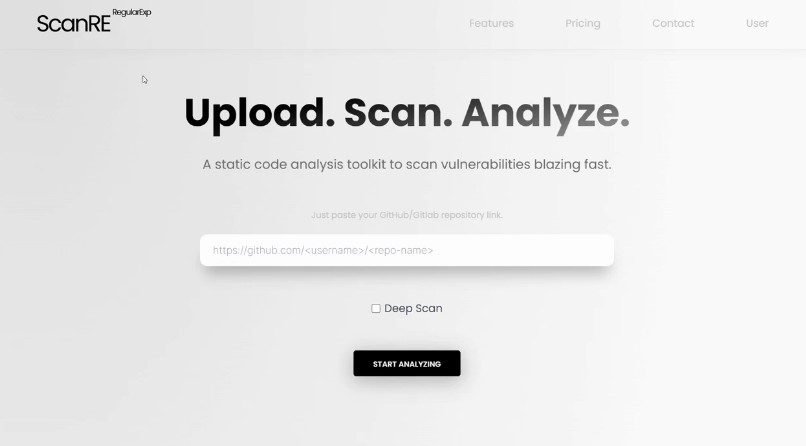
- Prompt the user to enter a GitHub or GitLab URL

- A few facts to keep the user engaged while the tool generates reports

- Overview of scan results

- List of Findings

- Tracking Tool

|

|
|
Check the boxes for which vulnerabilites have been fixed. |
Vulnerability Fixed Percentage |
- Results in an easy to understand format along with severity, likelihood, file path and line number in which the vulnerability was detected, the CWE details and suggested mitigation strategy as well as past scan findings and vulnerability tracking.

Performance metrics
It made sense to include benchmarks to show expected performance from our system ? The time taken to complete a scan is totally dependent on the volume of code being scanned. Since the underlying system is primarily built on top of SemGrep, our performance is mainly determined by the performance of SemGrep. Semgrep is able to outperform GitGuardian and other code analysis tools, both, in terms of time taken and false positives flagged.

Tree matching has a nearly negligible cost when compared to most deep program analysis techniques, such as pointer analysis or symbolic execution, so this was clearly a winning battle. As Semgrep grew more advanced, more features were added which caused it to err closer to the side of semantics, such as taint analysis and constant propagation.
These analyses are not necessarily ones that can be done quickly. Taint analysis, in particular, requires running dataflow analysis over the entire control flow of a program, which can potentially be huge, when considering how large an entire codebase may be, with all of its function calls and tricky control flow logic. To do taint analysis in this way would be to pick a losing battle.
Semgrep succeeds in that it only carries out single-file analysis, so the control flow graph never exceeds the size of a file. In addition, taint can be done incrementally. Functions have well-defined points where they begin and end, as well as generally well-defined entrances in terms of the data they accept (the function arguments). Thus, Semgrep collects taint summaries, which essentially (per function) encode the information about what taint may be possible, depending on the taint of the inputs that flow in.

Business Model

We’re almost certain we’ve forgotten something ?