Storybook extractor
? This project was done as a part of 24h design systems hackathon 2022 there are some known issues as a result of that.
Storybook extractor is a tool that extracts data from storybook stories, documentation pages and generates a JSON file with them.
Features:
- Extracts metadata from storybook globals
- Takes a screenshot of the storybook component
- Extracts docs page HTML
Running storybook-extractor on URL where storybook is running will output JSON like this:
Click to see complete JSON
Some of the properties are shorten for readability.
{
"id": "2788c0bf91f7bef230a70af70851b7e0",
"title": "ButtonPrimary/Playground",
"storyPath": "Core/Button/ButtonPrimary",
"storyName": "Playground",
"storyId": "core-button-buttonprimary--playground",
"componentName": "ButtonPrimary",
"docs": {
"heading": "ButtonPrimary",
"firstParagraph": "ButtonPrimary is a button used for main actions on page",
"tablesHtml": [
"<first-found-html-table>",
],
"codeSnippets": [],
"fullText": "<inner-text-of-docs>"
},
"urls": {
"storyUrl": "http://localhost:4400/?path=/story/core-button-buttonprimary--playground",
"storyUrlIframe": "http://localhost:4400/iframe.html?id=core-button-buttonprimary--playground&args=&viewMode=story",
"docsUrl": "http://localhost:4400/?path=/docs/core-button-buttonprimary--playground",
"docsUrlIframe": "http://localhost:4400/iframe.html?id=core-button-buttonprimary--playground&viewMode=docs"
},
"pictureBase64": "<base64-of-your-component>",
"raw": {
"id": "core-button-buttonprimary--playground",
"kind": "Core/Button/ButtonPrimary",
"name": "Playground",
"story": "Playground",
"parameters": {
"docs": {
"inlineStories": true,
"iframeHeight": 100
},
"backgrounds": {
"grid": {
"cellSize": 20,
"opacity": 0.5,
"cellAmount": 5
},
"values": [
{
"name": "light",
"value": "#F8F8F8"
},
{
"name": "dark",
"value": "#333333"
}
]
},
"globals": {
"measureEnabled": false,
"outline": false
},
"framework": "react",
"component": {
"__docgenInfo": {
"description": "ButtonPrimary component\nUsage: should be used for main actions on page\n",
"methods": [],
"displayName": "ButtonPrimary"
}
},
"fileName": "<path>/button-primary.stories.tsx",
"storySource": {
"source": "<story-source-code>",
"locationsMap": {
}
},
"args": {},
"argTypes": {},
"__id": "core-button-buttonprimary--playground",
"__isArgsStory": false
},
"args": {},
"initialArgs": {}
},
}
With this raw JSON report you can generate what do you desire, for example:
- Generate snippets for IDE with all components from storybook
- Get storybook docs pages into your custom documentation page
- Feed Algolia search with you components data
Install
npm install --save-dev storybook-extractor
Usage
You need to run the extractor with a path to a config file.
npx storybook-extractor -c /path/to/storybook-extractor.config.js
Config file arguments
| Argument | Type | Description |
|---|---|---|
| url | string | URL to storybook instance |
| output | string | Path to output file |
| concurentScrapers | number | Number of concurrent scrapers, defaults to 20 |
| postProcess | String[] | Path to post processor |
Example config file
module.exports = {
url: "http://localhost:4400",
output: "./out.json",
concurentScrapers: 20,
postProcess: ["./examples/example-post-process.js"],
};
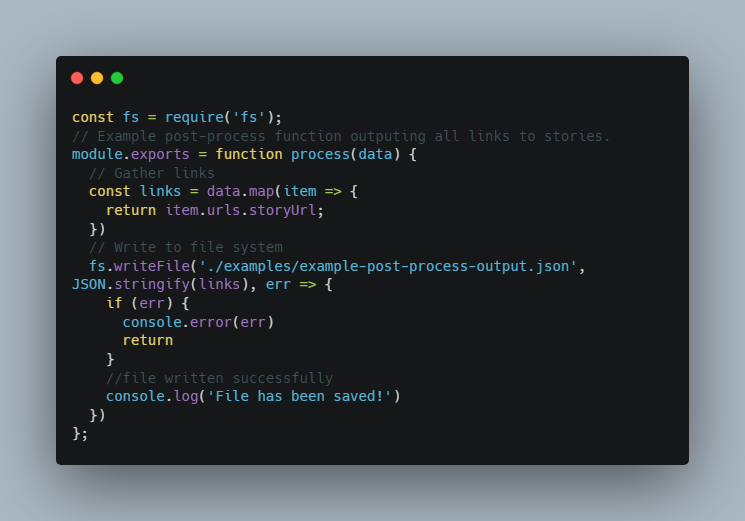
Custom post process
This extractor only produces raw data which can be quite large, because of that there is an option to specify postProcess in your config file to run scripts after extractor, like this:
postProcess: [".path/to/your/script.js"],
After the extractor is finished scraping it will execute specified processes. Note that those processes are not chained.
Known issues
- Docs pages are being scraped multiple times. As for a component you can have multiple stories which have unique URLs and previews but don’t have unique doc pages.
- Not everything is TS typed
- The Config file is required right now, having CLI commands would be more friendly
- No tests
License
MIT