myAlgorithm (beta)
Your own self hosted recommendation feed based on your browsing habits.
myAlgorithm is a chrome extension (firefox version now available) I made for myself to have more control over my recommendation feeds. It tracks and stores your browsing habits (searches, clicks, content engagements, text input) locally and web scraped various search engines (right now google, duckduckgo, and yandex) with auto-generated search queries.
As for privacy and security, the only server interactions made in the app are the web scraping routines (using fetch API) to make the search engine queries. Otherwise, all the data (tracking data and settings) is stored locally in browser to avoid any privacy concerns.
This project is a work in progress and available for anyone to test in the meantime.
If you like myAlgorithm and would like more tools to escape the Google algorithm donate here —> https://www.buymeacoffee.com/bjGHFVW355 In the near future, I plan on working on these projects full time.
Here’s the discord if you’re interested in getting involved/contacting the developer (me) https://discord.gg/C6sYF48f
Version
0.4.1
Todo (upcoming features)
Firefox version(complete)Ability to add your own sources by domain(complete)- Topic reporting on Content items in feed
(create GitHub issue or join discord if you have any feature requests)
Install
Download the Chrome extension here.
If you want to run the developer version (most up to date)
Fork the repo and then follow this tutorial on loading an unpacked extension in Chrome/Firefox
https://webkul.com/blog/how-to-install-the-unpacked-extension-in-chrome/
https://blog.mozilla.org/addons/2015/12/23/loading-temporary-add-ons/
How to use?
Simply use your browser like normal. Go to news articles, watch videos, tweet, post. In realtime you’ll be able to see topics relating to your usage in the extension popup.
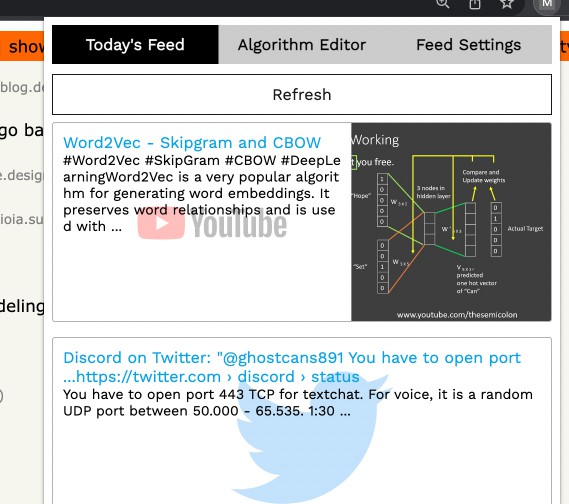
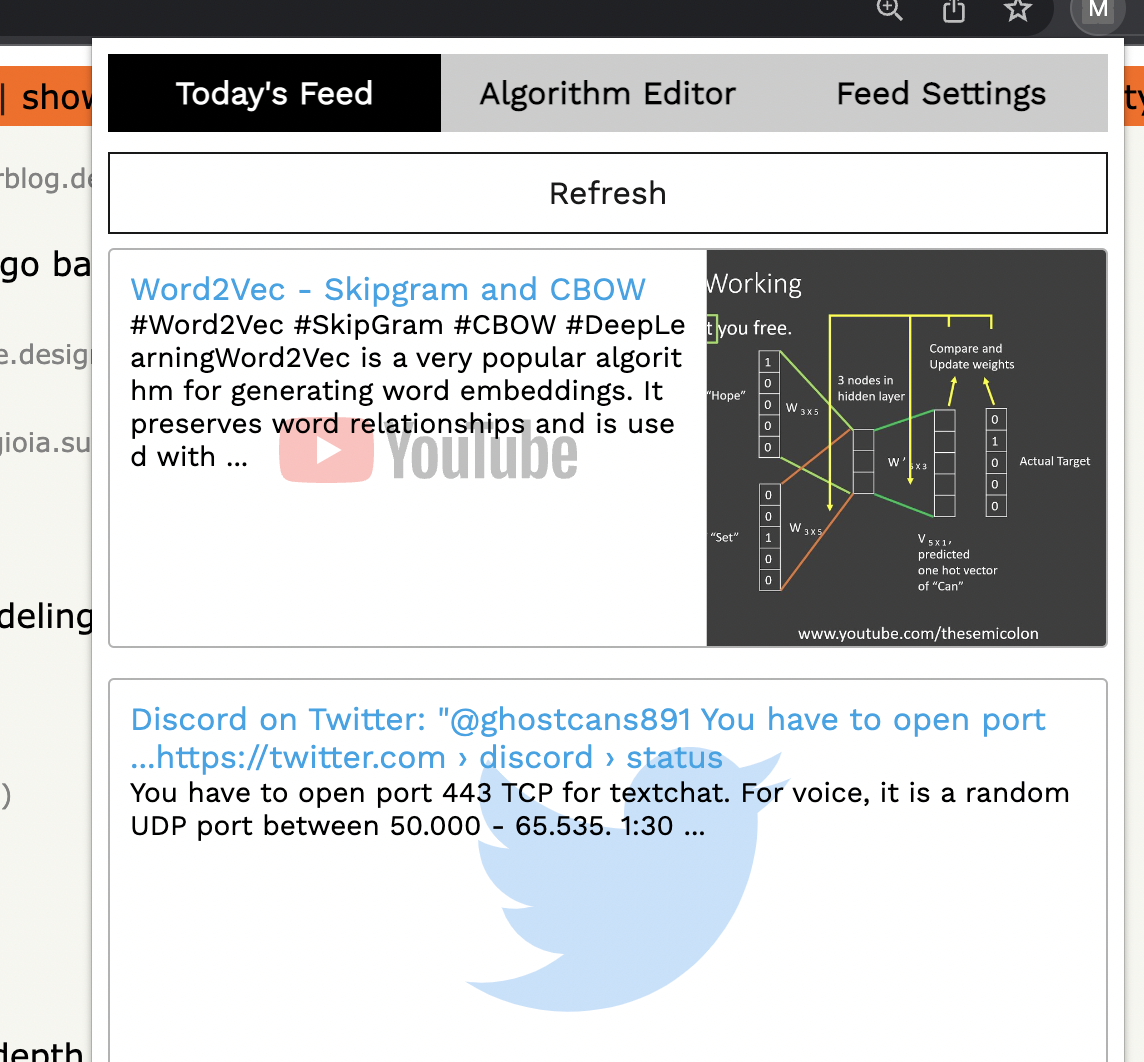
The Content Feed
You will get a daily feed of content (also an option to refresh at will) after 6am everyday. It will have roughly 10 pieces of content from on your allowed sources (youtube videos, twitter posts, reddit posts, etc.) based on your browsing habits
Algorithm Editor
The Algorithm Editor is a dashboard to view and edit your recommendation algorithm. You can see two graphs detailing your overall browsing habits. Below you have the option to view, add and remove all of the topics that will be used in the web scraping routines (these are ranked by occurrences, ranking prorities and partially randomized)

Feed settings
You are able to switch on and off which content sources you want and don’t want. You can also set the ranking priorities you want for the recommendation algorithm. In addition there’s a Refresh mode to update the content feed whenever (warning Refresh mode can cause rate limiting in google/yandex if you run it too often)

How it works
The recommendation algorithm collects keywords from your browsing habits and runs an LDA topic model to gather the prioritized terms to use to web scrape for content. The web scraping uses search queries from these topics to parse from major search engines (Google, Yandex, DuckDuckGo) to get content related to your habits.
Build Instructions
If you want to build from source follow the instructions below
Prerequisites
- You must have the latest Node/NPM installed
In the root of the repository run
$ npm install
This downloads all of the packages you need
Then run the chrome build
$ npm run build:chrome
Run the firefox build
$ npm run build:firefox
And you’re done.
Most of the code is in the shared folder. There are two nearly identical webpack configs (1 for chrome, 1 for firefox) that generate builds for the background/content scripts and the react popup frontend.