Video/Audio Transcriber
An OpenAI’s Whisper-based full-stack project to transcribe audio and video files using React & Django.
Demo

Installation
You need the latest versions of pipenv and node to setup this project.
- First clone the repository
git clone https://github.com/ali-h-kudeir/transcribe-video-audioand navigate to the project’s foldercd transcribe-video-audio - Install the dependencies of both the client and server.
- Run both the client and server separately
- Go to http//localhost:3000 to upload and transcribe your media files.
1- To install the server’s dependencies, in the terminal run the following:
cd api
pipenv install
pipenv shell
pipenv run python manage.py makemigrations
pipenv run python manage.py migrate
pipenv run server
- Navigate to navigate to http://localhost:8000 to check if the server was setup successfully.
2- To run the client, execute the following commands:
cd client
yarn install
touch .env.local
yarn dev
You need to have the following env variables in your .env.local file:
NEXT_PUBLIC_ROOT_URL=http://127.0.0.1:8000
NEXT_PUBLIC_ALL_FILES_URL=http://127.0.0.1:8000/api/transcription/files/
NEXT_PUBLIC_FILE_UPLOAD_URL=http://127.0.0.1:8000/api/transcription/files/
NEXT_PUBLIC_TRANSCRIPTION_URL=ws://127.0.0.1:8000/ws/transcribe
Adjust these if your going to deploy to any remote server.
- Navigate to http://localhost:3000/ to see if the client is working and the file upload section is visible.
- Since this project uses websockets to send realtime-messages between the client and server, you need to see if the console of the client is showing connected, which means both client and server can exchange messages.
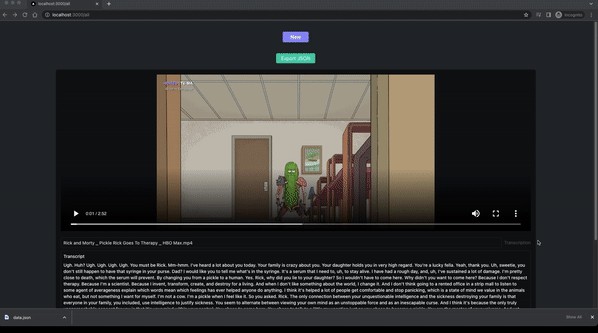
3- Select a video or audio file to upload The transcripts will be extracted and displayed on the page.
4- You can also view all your uploaded video and audio files and see their transcriptions. Their is an additional export button that allows you to download a JSON file with all their information.
- Note that this project only allows MP4, and MP3 format files.
- Additional Notes Make sure ffmpeg is installed on your machine and available on your system’s PATH
License
Contributing
Contributions are always welcome!
Open a PR or an issue for extra features and bug fixes.