Introduction
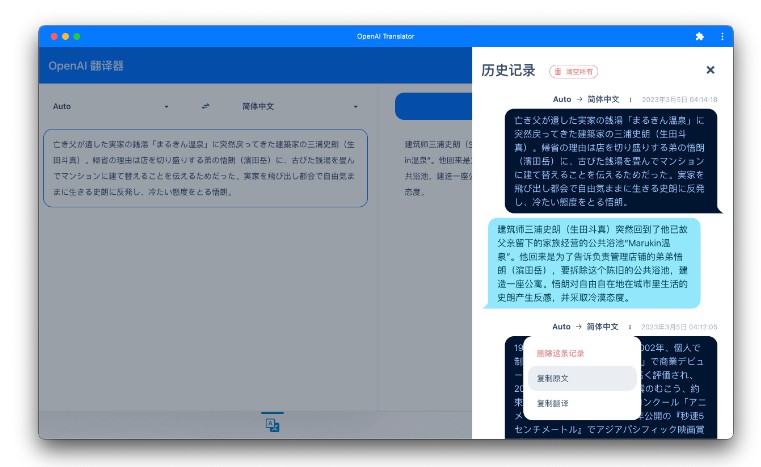
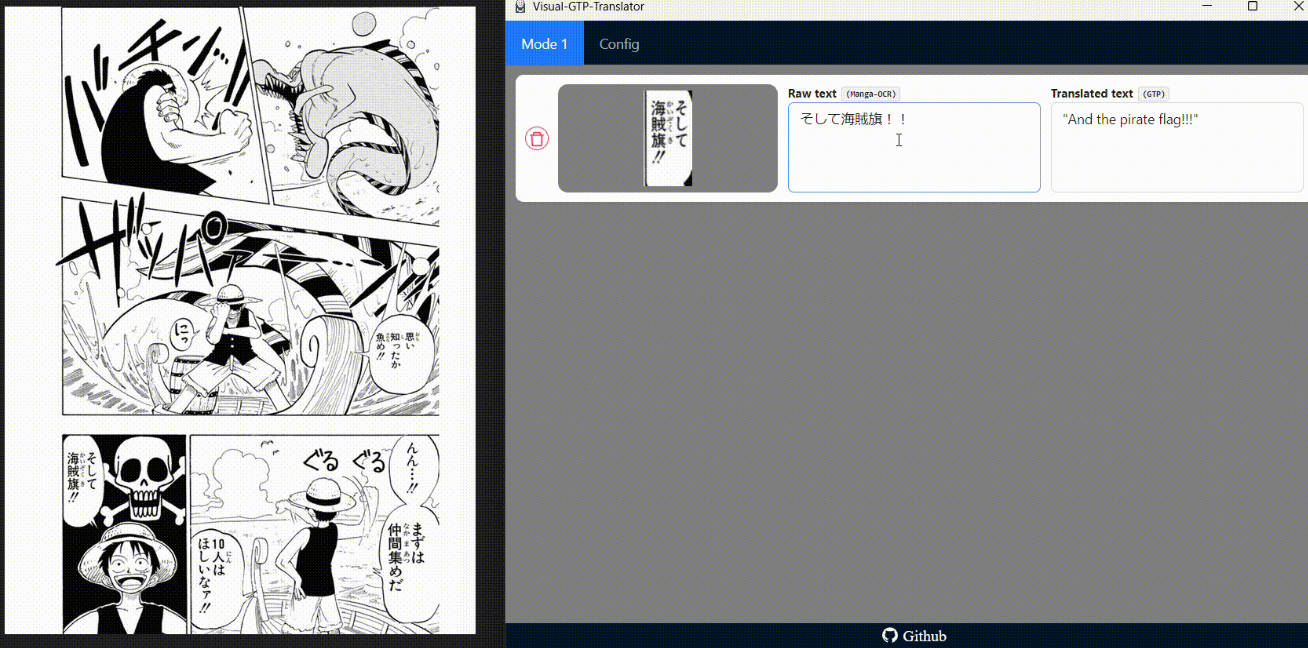
Program with a graphical interface for taking screenshots and translating Japanese text to another language found in those screenshots. The system uses Manga-OCR for detecting Japanese characters in the images, and the OpenAI API to utilize the GPT Models for translating the text.

There are configurations available to change the image capture shortcut and also the base prompt to use for translation with GPT. The program starts a FastAPI based server for processing images and interfacing with OpenAI. The graphical interface is built using a combination of ElectronJS and ReactJS.
A compiled .exe version (using PyInstaller and electron-packager) is provided for quick installation. The installer has an approximate file size of 220Mb. After the program is installed, it automatically downloads the model used by Manga-OCR for character detection. This model has a file size of 450Mb.
Download executable:
- From: Github Release
- From: Anonfiles
- From: Gofile
Currently, the program only works on Windows.
Install and execute from code:
- Have Node 16.X installed.
- Have Python 3.9 and Poetry installed.
- Download the repo.
- Install the server (backend) dependencies using:
poetry shelland thenpoetry install - Install the graphical interface dependencies (frontend) with:
npm install - Start project in development mode with:
poetry shelland thennpm run electron-dev
Build executables
This process is not yet fully automated. First, we need to compile the server using PyInstaller. After that, compile ElectronJS using electron-packager. Finally, combine the results of these two processes in a final folder that we can compress into an installer
- Run PyInstaller inside the backend directory:
cd backendthenpoetry shelland thenpyinstaller mangaOcrApi.spec. This should generate a folder named “dist” with the compiled server. - Build the ReactJS bundle with:
npm run electron-buildand then compile the ElectronJS application with:npm run package. This should generate a folder named “release-builds” with the compiled frontend. - Go to “release-builds/VGT-win32-x64” and create a directory named “backend”. Copy the folder located at “backend/dist” inside this directory. The “release-builds” folder should look like this:
--release-builds
----backend
------mangaOcrApi
- We can compress this folder into an installer using WinRaR.
Limitations:
- Requires an OpenAI API KEY
- Only recognizes Japanese characters
- Only works on Windows
The system is divided into 2 parts:
-
A graphical interface based on ElectronJs and ReactJs (Javascript). This layer allows interaction with the user and captures images from the screen.
-
A local server based on FastAPI (Python). This performs image analysis for character extraction (OCR) and communication with online services such as the GPT API.
When ElectronJS is started, it takes care of running the server as a child process.
To-do list:
- Allow selecting multiple GPT models.
- Possibility to resort to other translators, such as DeepL.
- Add options to use other OCRs to detect other languages.
- Add functionality to support multiple monitors.
- Allow creating pipelines to combine the results of various OCR and/or translators (bagging) to improve the final performance.
Future experiments:
- Use the translation history to improve GPT results. This way, context can be added to the entries to be translated.
- Use multiple languages as intermediaries to improve GPT results. For example, translate a text to four different languages and then request to combine those results into a final language.
- Implement other translators, such as DeepL, Google, and Yandex, to combine multiple translations into a better one.
Base on boilerplate:
Media: