OpenAI Streaming Hooks
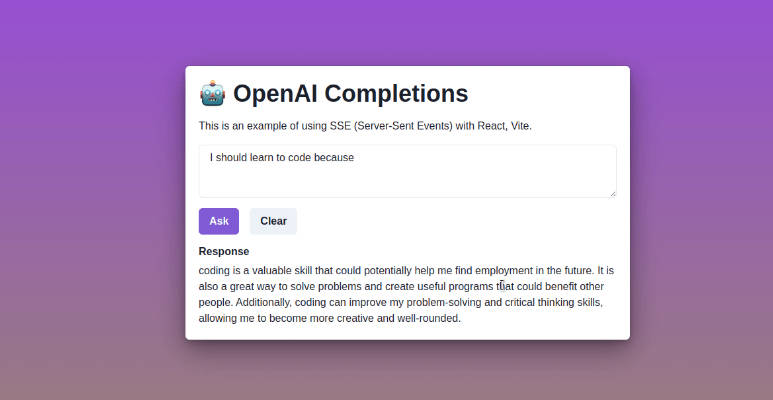
Talk directly to OpenAI Completion APIs and stream the response back in real-time in the browser–no server required.
Provides custom React Hooks capable of calling OpenAI Completions APIs with streaming support enabled by Server-Sent Events (SSE).
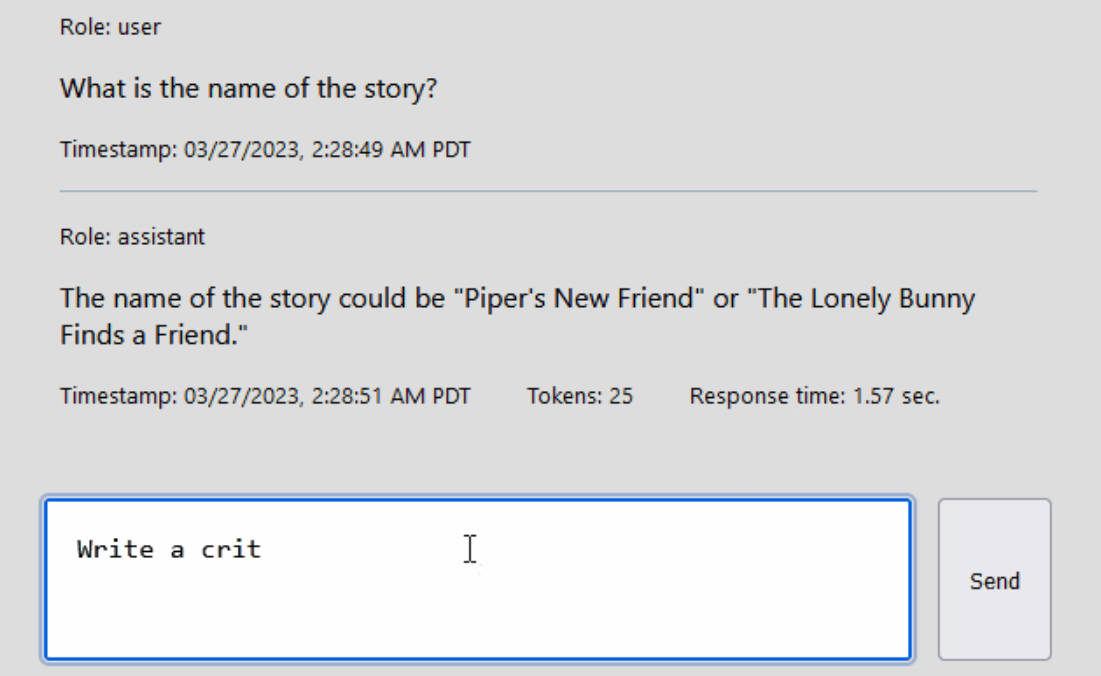
Example

Use
- Install the OpenAI Streaming Hooks library:
npm install --save openai-streaming-hooks@https://github.com/jonrhall/openai-streaming-hooks
- Import the hook and use it:
import { useChatCompletion, GPT35 } from 'openai-streaming-hooks';
const Component = () => {
const [messages, submitMessage] = useChatCompletion({
model: GPT35.TURBO,
apiKey: 'your-api-key',
});
...
};
Supported Types of Completions
There are two main types of completions available from OpenAI that are supported here:
- Text Completions, which includes models like
text-davinci-003. - Chat Completions, which includes models like
gpt-4andgpt-3.5-turbo.
There are some pretty big fundamental differences in the way these models are supported on the API side. Chat Completions consider the context of previous messages when making the next completion. Text Completions only consider the context passed into the explicit message it is currently answering.
The custom React Hooks in this library try to normalize this behavior by returning the same tuple structure of [messages, submitMessage] to the React component regardless of the type of Completion used.
The structure of a message object inside of messages differs based on the type of Completion.
Chat Completions
An individual message in a Chat Completion’s messages list looks like:
interface ChatMessage {
content: string; // The content of the completion
role: string; // The role of the person/AI in the message
timestamp: number; // The timestamp of when the completion finished
meta: {
loading: boolean; // If the completion is still being executed
responseTime: string; // The total elapsed time the completion took
chunks: ChatMessageToken[]; // The chunks returned as a part of streaming the execution of the completion
};
}
Each chunk corresponds to a token streamed back to the client in the completion. A ChatMessageToken is the base incremental shape that content in the stream returned from the OpenAI API looks like:
interface ChatMessageToken {
content: string; // The partial content, if any, received in the chunk
role: string; // The role, if any, received in the chunk
timestamp: number; // The time the chunk was received
}
When the submitMessage function is called two new chat messages are appended to the messages state variable:
- The first is the message that you just submitted with a
roleof typeUser - The second is the message that content will be streamed into in real-time as the OpenAI completion executes.