LLM Voice Chat
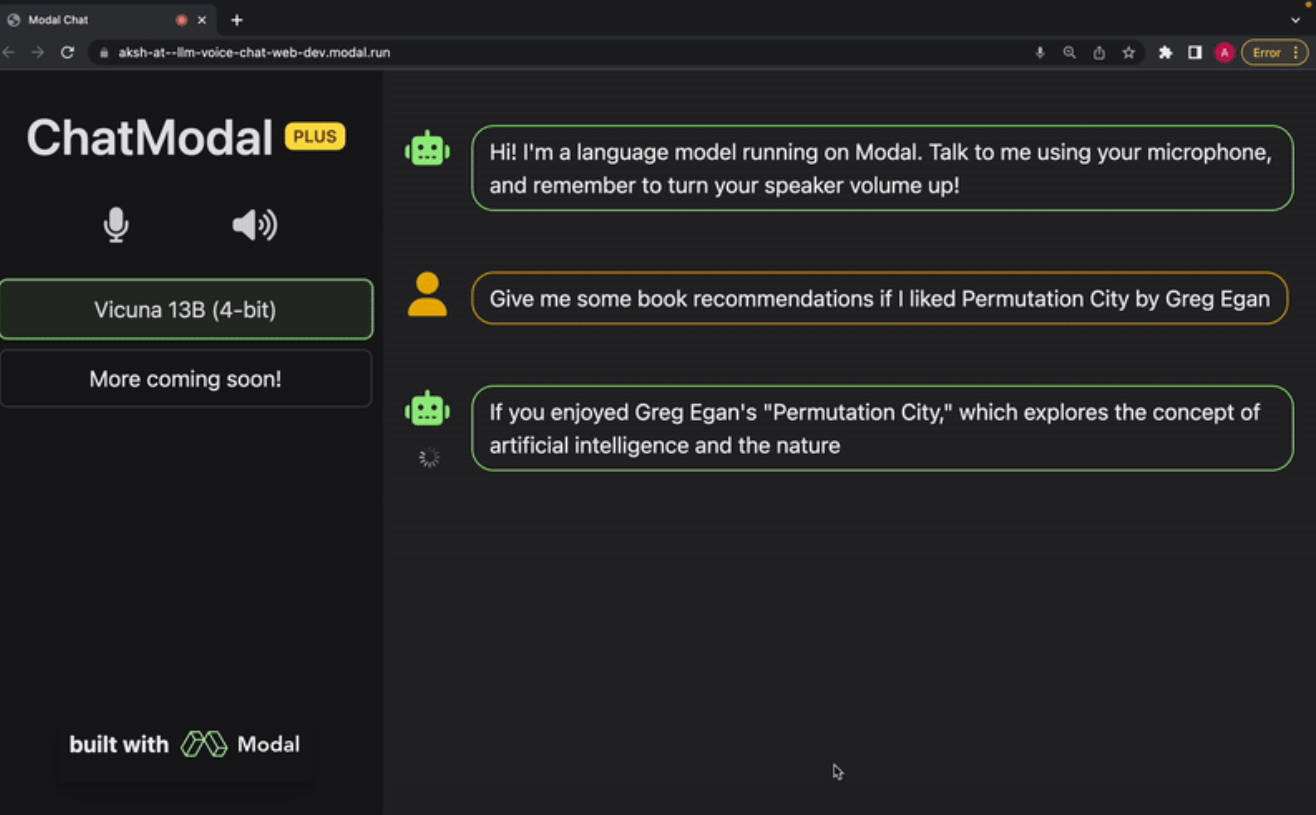
A complete chat application that lets you interface with a large language model using just your voice, and reads the responses back to you with realistic, natural-sounding speech.
This repo is meant to serve as a starting point for your own language model-based apps, as well as a playground for experimentation. Contributions are welcome and encouraged!
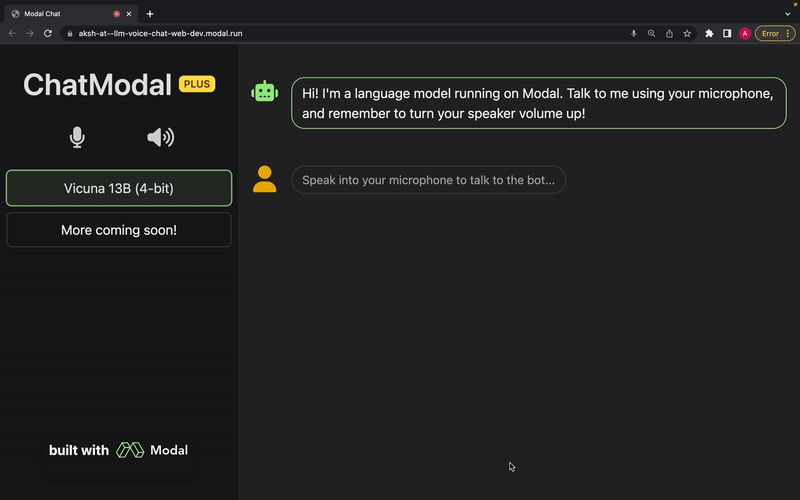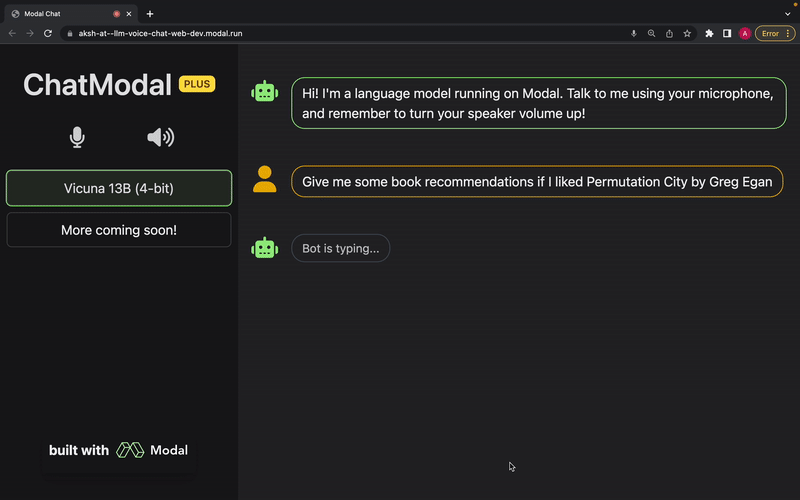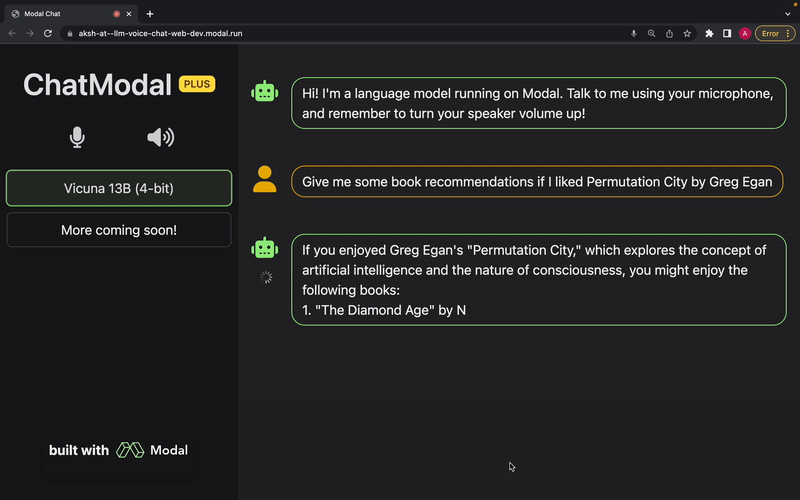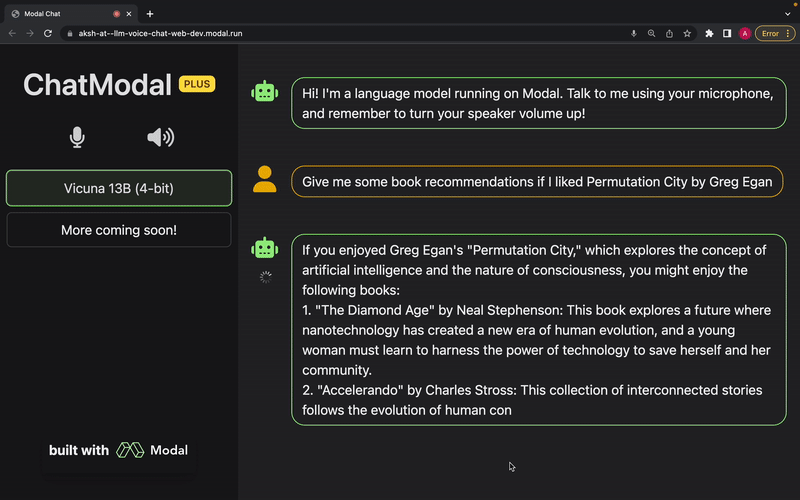
The language model used is Vicuna, and we’re planning on adding support for more models soon (requests and contributions welcome). OpenAI Whisper is used for transcription, and Metavoice Tortoise TTS is used for text-to-speech. The entire app, including the frontend, is made to be deployed serverlessly on Modal.
You can find the demo live here.
[Note: this code is provided for illustration only; please remember to check the license before using any model for commercial purposes.]
File structure
- React frontend (
src/frontend/) - FastAPI server (
src/api.py) - Whisper transcription module (
src/transcriber.py) - Tortoise text-to-speech module (
src/tts.py) - Vicuna language model module (
src/llm_vicuna.py)
Developing locally
Requirements
modal-clientinstalled in your current Python virtual environment (pip install modal-client)- A Modal account
- A Modal token set up in your environment (
modal token new)
Develop on Modal
To serve the app on Modal, run this command from the root directory of this repo:
modal serve src.app
In the terminal output, you’ll find a URL that you can visit to use your app. While the modal serve process is running, changes to any of the project files will be automatically applied. Ctrl+C will stop the app.
Deploy to Modal
Once you’re happy with your changes, deploy your app:
modal deploy src.app
[Note that leaving the app deployed on Modal doesn’t cost you anything! Modal apps are serverless and scale to 0 when not in use.]