ArchivEye Description
ArchivEye is an offline PDF OCR tool developed to safeguard the privacy and confidentiality of sensitive documents.
This user-friendly GUI application is designed for professionals like lawyers, OSINT researchers, journalists, and others who often work with PDF documents.
ArchivEye’s OCR technology enables users to search through scanned and non-searchable PDF files without uploading them to the cloud, offering added privacy and security.
The software prioritizes ease of use, allowing even those without technical expertise to navigate and use it smoothly. By offering a unified interface for searching and indexing multiple PDF documents within a folder, ArchivEye streamlines tasks such as opening numerous PDFs, reading, manual note-taking, and cross-referencing information, saving users valuable time.
Installation
Prerequisites
ArchivEye requires Tesseract and GhostScript to be installed on your system.
Follow the steps below to install these third-party tools
Install Tesseract
Tesseract is an integral part of ArchivEye, providing powerful OCR capabilities that convert extracted individual pages into searchable text.
Download and install the latest version 5.3.1 from uni-mannheim
Install GhostScript
GhostScript is used to extract individual pages from the PDF file as images for Tesseract to OCR.
Go to this page and download and install gs10011w64.exe
Download ArchivEye
Simply go to the Release section of this Github page and download the .exe file, double click and it will install automatically
Usage
First Time Setup
During the first-time setup, you will need to configure the tool by specifying the paths to the installed Tesseract and GhostScript tools. Use the Select buttons for Tesseract and GhostScript:
-
For
Tesseract, select the folderTesseract-OCR -
For
GhostScript, be sure to select the folder that is insidegsbut notgsitself, in the time of releasing this version of ArchivEye, mine would begs10.01.1
Don’t worry if you accidentally select the wrong paths, the Validate & Proceed button will validate the paths to make sure the paths are correct before we start indexing PDFs. It will also automatically run both the Ghostscript and Tesseract binaries on a dummy PDF to make sure these third party tools are working as expected

Indexing

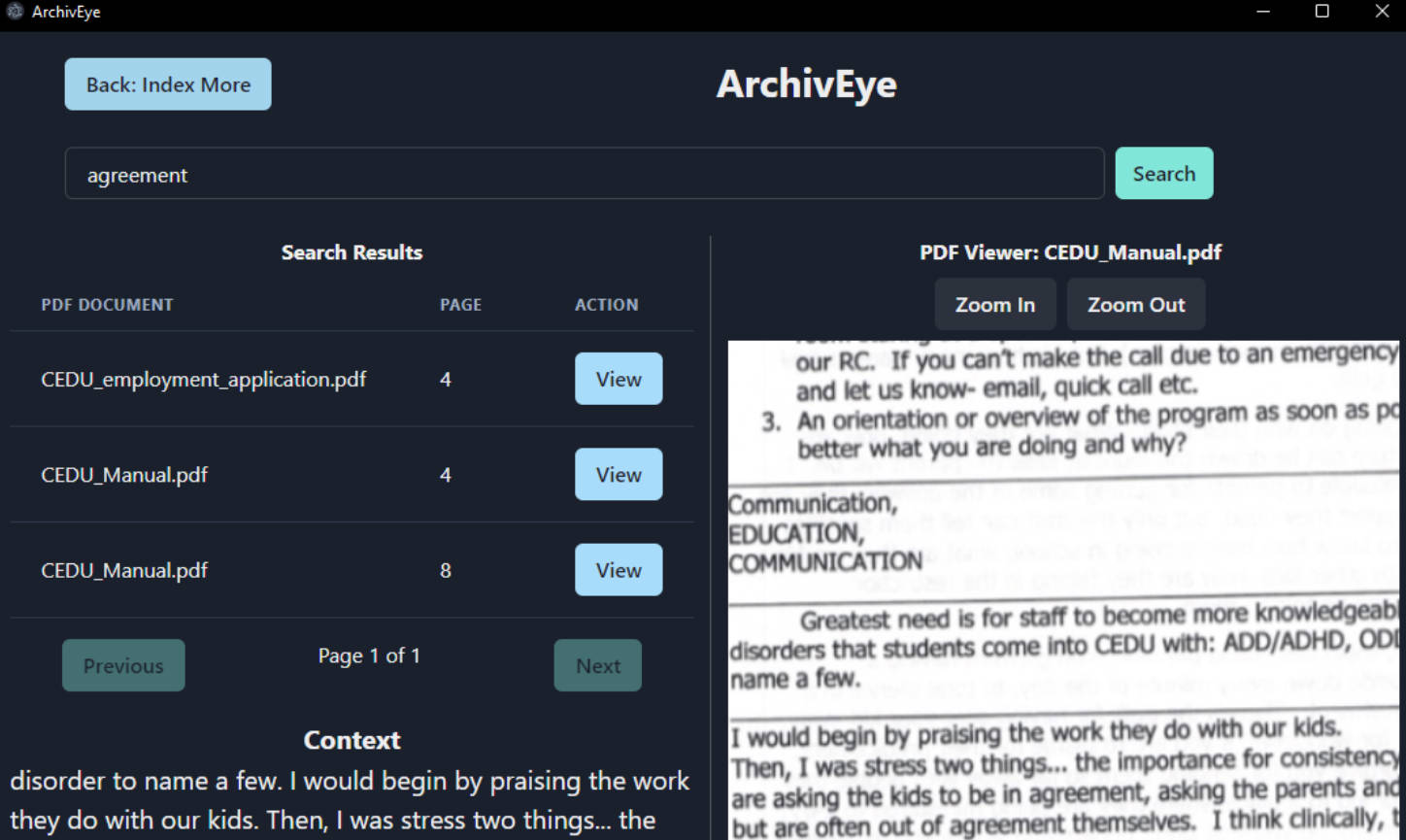
Search

Additional Information: Design
Architecture Choice
This tool prioritizes accessibility and privacy, so web apps and command-line tools are not suitable options.
OCR capability is necessary, which initially suggests using Python with GUI libraries (e.g., PyQT5/Tkinter). However, these don’t provide the same aesthetic appeal as a browser-based frontend built with React.
Ultimately, an Electron app is chosen. Combining Electron with Python is possible, but integrating them proved challenging due to my limited experience with webpacks. As a result, I opted for Electron + Next.js = Nextron and Node.js.
Indexing Design
For each PDF document, we generate a UUID to represent it.
A “master” record containing all generated UUIDs and their corresponding filesystem paths is also generated.
OCR Design
This tool aims to search scanned PDF documents on a per-page basis. To achieve this, we need to extract every single page from a PDF document, perform OCR on the resulting images, and generate text files for each page.
Ghostscript is used to extract individual PDF pages into images, while Tesseract handles OCR for each image. After OCR is completed for a PDF document, the per-page images are deleted from the filesystem.
Search Logic
To display search results on a per-page basis, we store per-page text files and perform search operations as if conducting a recursive directory search.
This process involves scanning each folder named by the UUID of the PDF document and searching through each text file to return the page number associated with its PDF document.
Limitations
- OCR can be slow, particularly for PDF documents with hundreds of pages. Processing time may vary depending on your PC hardware specifications. This can be resolved by utilizing multithreading.
- It only supports English language for now due to time constraint.