useWhisper
React Hook for OpenAI Whisper API with speech recorder, real-time transcription and silence removal built-in
- Demo
-
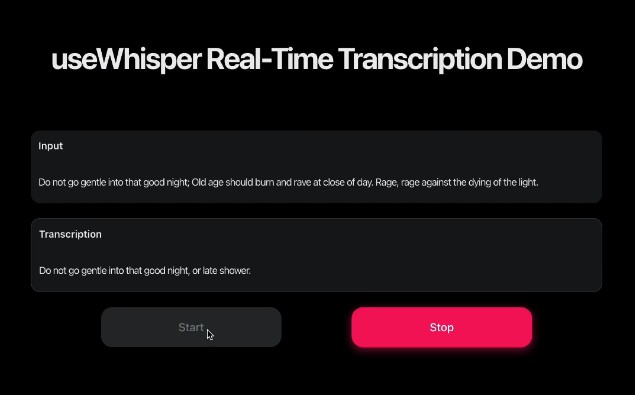
Real-Time transcription demo
-
Install
npm i @chengsokdara/use-whisper
yarn add @chengsokdara/use-whisper
-
Usage
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const {
recording,
speaking,
transcribing,
transcript,
pauseRecording,
startRecording,
stopRecording,
} = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
})
return (
<div>
<p>Recording: {recording}</p>
<p>Speaking: {speaking}</p>
<p>Transcribing: {transcribing}</p>
<p>Transcribed Text: {transcript.text}</p>
<button onClick={() => startRecording()}>Start</button>
<button onClick={() => pauseRecording()}>Pause</button>
<button onClick={() => stopRecording()}>Stop</button>
</div>
)
}
-
Custom Server (keep OpenAI API token secure)
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
/**
* you have more control like this
* do whatever you want with the recorded speech
* send it to your own custom server
* and return the response back to useWhisper
*/
const onTranscribe = (blob: Blob) => {
const base64 = await new Promise<string | ArrayBuffer | null>(
(resolve) => {
const reader = new FileReader()
reader.onloadend = () => resolve(reader.result)
reader.readAsDataURL(blob)
}
)
const body = JSON.stringify({ file: base64, model: 'whisper-1' })
const headers = { 'Content-Type': 'application/json' }
const { default: axios } = await import('axios')
const response = await axios.post('/api/whisper', body, {
headers,
})
const { text } = await response.data
// you must return result from your server in Transcript format
return {
blob,
text,
}
}
const { transcript } = useWhisper({
// callback to handle transcription with custom server
onTranscribe,
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Examples
-
Real-time streaming trascription
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const { transcript } = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
streaming: true,
timeSlice: 1_000, // 1 second
whisperConfig: {
language: 'en',
},
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Remove silence before sending to Whisper to save cost
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const { transcript } = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
// use ffmpeg-wasp to remove silence from recorded speech
removeSilence: true,
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Auto start recording on component mounted
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const { transcript } = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
// will auto start recording speech upon component mounted
autoStart: true,
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Keep recording as long as the user is speaking
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const { transcript } = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
nonStop: true, // keep recording as long as the user is speaking
stopTimeout: 5000, // auto stop after 5 seconds
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Customize Whisper API config when autoTranscribe is true
import { useWhisper } from '@chengsokdara/use-whisper'
const App = () => {
const { transcript } = useWhisper({
apiKey: process.env.OPENAI_API_TOKEN, // YOUR_OPEN_AI_TOKEN
autoTranscribe: true,
whisperConfig: {
prompt: 'previous conversation', // you can pass previous conversation for context
response_format: 'text', // output text instead of json
temperature: 0.8, // random output
language: 'es', // Spanish
},
})
return (
<div>
<p>{transcript.text}</p>
</div>
)
}
-
Dependencies
- @chengsokdara/react-hooks-async asynchronous react hooks
- recordrtc: cross-browser audio recorder
- @ffmpeg/ffmpeg: for silence removal feature
- hark: for speaking detection
- axios: since fetch does not work with Whisper endpoint
most of these dependecies are lazy loaded, so it is only imported when it is needed
-
API
-
Config Object
| Name | Type | Default Value | Description |
|---|---|---|---|
| apiKey | string | ” | your OpenAI API token |
| autoStart | boolean | false | auto start speech recording on component mount |
| autoTranscribe | boolean | true | should auto transcribe after stop recording |
| nonStop | boolean | false | if true, record will auto stop after stopTimeout. However if user keep on speaking, the recorder will keep recording |
| removeSilence | boolean | false | remove silence before sending file to OpenAI API |
| stopTimeout | number | 5,000 ms | if nonStop is true, this become required. This control when the recorder auto stop |
| streaming | boolean | false | transcribe speech in real-time based on timeSlice |
| timeSlice | number | 2000 ms | interval between each onDataAvailable event |
| whisperConfig | WhisperApiConfig | undefined | Whisper API transcription config |
| onDataAvailable | (blob: Blob) => void | undefined | callback function for getting recorded blob in interval between timeSlice |
| onTranscribe | (blob: Blob) => Promise<Transcript> | undefined | callback function to handle transcription on your own custom server |
-
WhisperApiConfig
| Name | Type | Default Value | Description |
|---|---|---|---|
| prompt | string | undefined | An optional text to guide the model’s style or continue a previous audio segment. The prompt should match the audio language. |
| response_format | string | json | The format of the transcript output, in one of these options: json, text, srt, verbose_json, or vtt. |
| temperature | number | 0 | The sampling temperature, between 0 and 1. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. If set to 0, the model will use log probability to automatically increase the temperature until certain thresholds are hit. |
| language | string | en | The language of the input audio. Supplying the input language in ISO-639-1 format will improve accuracy and latency. |
-
Return Object
| Name | Type | Description |
|---|---|---|
| recording | boolean | speech recording state |
| speaking | boolean | detect when user is speaking |
| transcribing | boolean | while removing silence from speech and send request to OpenAI Whisper API |
| transcript | Transcript | object return after Whisper transcription complete |
| pauseRecording | Promise | pause speech recording |
| startRecording | Promise | start speech recording |
| stopRecording | Promise | stop speech recording |
-
Transcript
| Name | Type | Description |
|---|---|---|
| blob | Blob | recorded speech in JavaScript Blob |
| text | string | transcribed text returned from Whisper API |
-
Roadmap
- react-native support, will be export as use-whisper/native